An AI coding agent by 2sum AI
Metis makes AI-agent spend
visible, governable, and cheaper.
Metis is an open-core LLM gateway and agent runtime. Point Claude Code, Cursor, or your own SDK at it; every turn is routed, evaluated, and cost-stamped per dev and per team. Devs keep their tools. Buyers finally get the bill broken down.
delegation, validated
8.3% – 26.1%
better cost-per-quality on a fan-out workload — sonnet planner + haiku workers vs sonnet-only-no-delegation, across three independent runs with a 19.9% midpoint (§A3-rev5/6/7).
model selection, honest
$0.0477 / quality
Pass C lands between haiku-only $0.0383 and sonnet-only $0.1176, with the K-NN routing sonnet to the one hard turn and haiku elsewhere. N=1 demo; §A3-rev7 did not generalize it.
prompt caching
22.8%
same-workload cost reduction in Run 3, with cache firing on 49 of 49 LLM calls after stable-prefix placement and padding.
$ metis chat .
model: sonnet-4.6 · workspace: ~/projects/metis
loaded MEMORY.md (1.4 KB) · USER.md (0.9 KB)
> refactor the auth middleware to use the new session store
[route] sonnet-4.6 (sticky) · capabilities ok
reading src/auth/middleware.py …
reading src/sessions/store.py …
I see three call sites that construct sessions inline.
I'll inject the store via the existing DI container instead —
matches the pattern in routing/registry.py.
[delegate] worker: haiku-4.5 · task: edit 3 files · est. $0.004
edit src/auth/middleware.py (+12 −7)
edit src/auth/handlers.py (+4 −3)
edit tests/auth/test_middleware.py (+18 −0)
turn cost: $0.011 · cumulative: $0.034 · cache hit 71%
>
cat docs/architecture.md
How it works.
One canonical message format. One routing chain that runs the same way whether you call it from the gateway or the agent loop. Every turn writes to a trace store and a pattern store; the next turn that looks like one we've seen routes against what worked last time.
your devs (claude code / cursor / openai-python / anthropic-python) │ │ one env var flipped: │ ANTHROPIC_BASE_URL=https://gw.your-co.com │ OPENAI_BASE_URL=https://gw.your-co.com/v1 ▼ ┌────────────────────────────────────────────────────────────────────┐ │ metis gateway (transparent /v1/chat/completions + /v1/messages)│ │ │ │ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │ │ │ canonical IR │ → │ routing │ → │ adapter │ → upstream│ │ │ (lossless) │ │ (7-slot chain)│ │ (anthropic / │ │ │ └──────────────┘ └──────┬───────┘ │ openai / │ │ │ │ │ openrouter) │ │ │ ┌─────────────────────────▼────────┐ └──────────────┘ │ │ │ pattern store (slot 4) │ │ │ │ K-NN over task fingerprints + │ ┌──────────────┐ │ │ │ cost-weighted outcome history │ ← │ evaluator │ │ │ └──────────────────────────────────┘ │ (hybrid LLM- │ │ │ │ as-judge) │ │ │ ┌──────────────────────────────────┐ └──────────────┘ │ │ │ prompt cache discipline │ │ │ │ stable prefix · 4500-5500 tok │ │ │ │ cache-floor padding │ │ │ └──────────────────────────────────┘ │ └────────────────┬───────────────────────────────────────────────────┘ │ every turn writes ▼ ┌────────────────────────────────────────────────────────────────────┐ │ trace store (SQLite WAL, ~4,800 events/sec, indexed expressions) │ │ · route.decided · llm.call_completed · pattern.matched │ │ · eval.completed · turn.completed · gateway.key_* │ └────────────────┬───────────────────────────────────────────────────┘ │ read by ▼ ┌────────────────────────────────────────────────────────────────────┐ │ analytics · /analytics/by_user · by_team · by_key · cost · quality│ │ audit · metis audit export · 12-event compliance subset │ │ metrics · Prometheus /metrics on gateway and server │ └────────────────────────────────────────────────────────────────────┘
Gateway-first deployment
The buyer flips one env var per dev tool. No client code changes; no workflow change. The gateway is per-request stateless — no session manager, no tool dispatcher, no memory inside someone else's agent. Cost attribution starts on call one.
Agent upgrade path
When you want the deeper savings — context shaping, skill activation, bounded memory, planner-worker delegation — the same canonical IR powers the agent loop via metis chat / tui / serve. Same routing engine, same trace store. Buyer chooses the floor.
grep -r "differentiator" docs/STRATEGY.md
What everyone else doesn't ship.
Multi-provider routing and cost tracking are table stakes now — OpenCode, Claude Code, Cline, Goose, Aider, and the gateway crowd all do it. The defensible work is four legs deep:
01
Bounded, agent-curated memory
MEMORY.md and USER.md cap at ~2 KB and ~1.5 KB per workspace. The agent adds, replaces, and consolidates entries on its own. Unbounded vector stores destroy context quality with run-off; bounded memory keeps it surgical. Letta is the only Series-A peer with the same eviction-is-a-feature stance.
02
Lossless canonical message format
One internal representation of messages, content blocks, tool calls, thinking blocks, cache_control. Provider adapters translate to and from each wire format. Mid-session model swaps work because the canonical state is provider-agnostic. LiteLLM ships a tool_use / cache_control / thinking-block bug roughly every release; Metis doesn't.
03
Task-fingerprint pattern learning
Every turn writes a structural fingerprint plus the actual outcome (quality, cost, latency) to a per-workspace SQLite store. The next turn that looks like one we've seen routes against a K-NN cluster of cross-model outcomes. No commodity router ships this. First end-to-end inversion demonstration in benchmarks/RESULTS.md §A3-rev3.
04
Auto-derived skill curation
Periodic auxiliary-model maintenance of agent-authored skills: pin, archive, consolidate, edit. Never auto-deletes (archive is reversible). Pinned bypasses every auto-transition. agentskills.io-compatible. Pattern lifted from hermes-agent; gated on Phase 2.5 skill_save. Composes with pattern learning — leg 3 picks the right model per task class, leg 4 keeps the skill library that informs those tasks pruned and current.
Legs 3 and 4 compose: pattern learning picks the right model per task class; skill curation keeps the skill library that informs those tasks pruned and current. Each makes the other more valuable.
curl http://gateway/analytics/by_team
See where every cent goes.
Every turn, every model, every dollar — measured against what it would have cost on a single-model baseline, with per-user, per-team, and per-project rollups. The counterfactual is the same one the gateway uses live; no spreadsheet math.
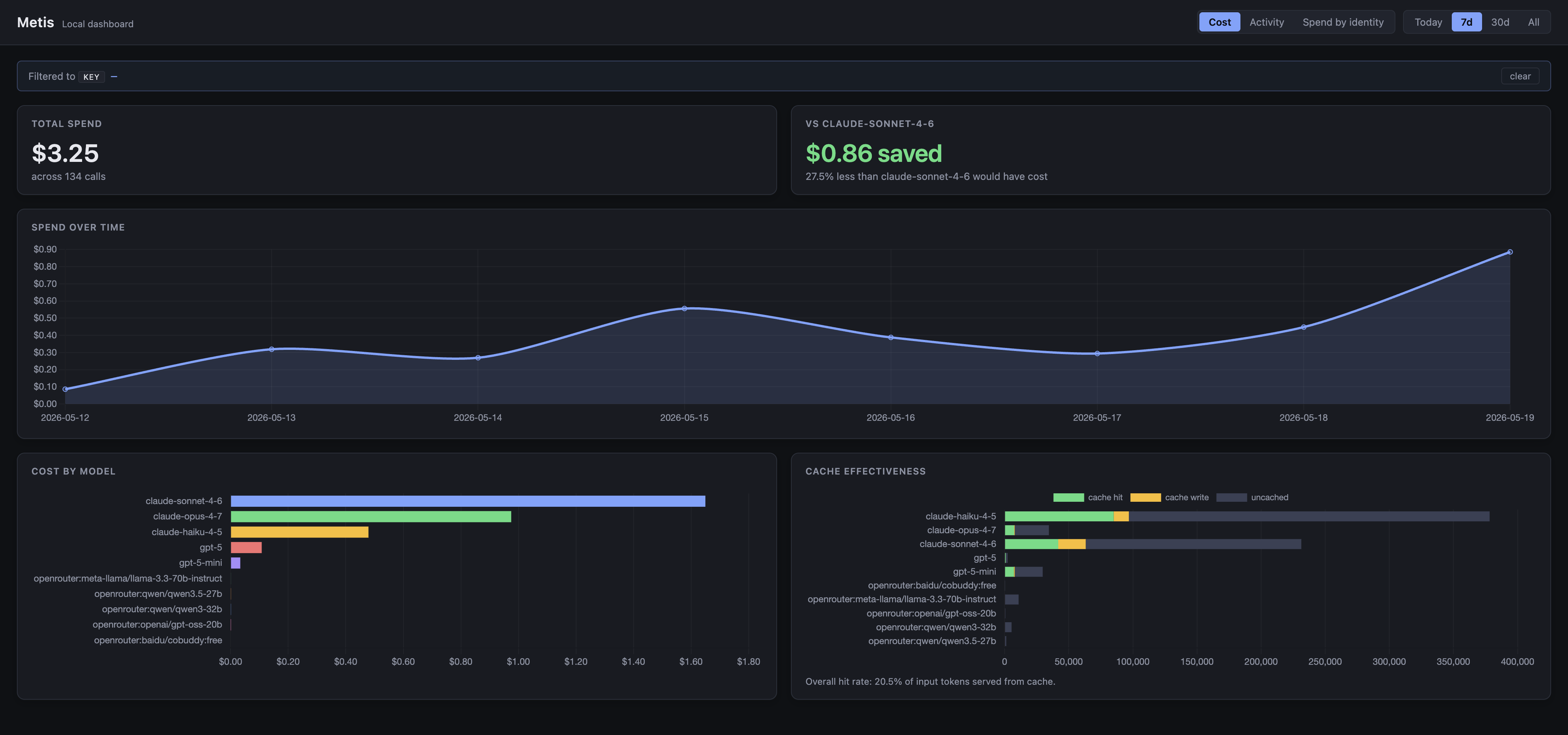
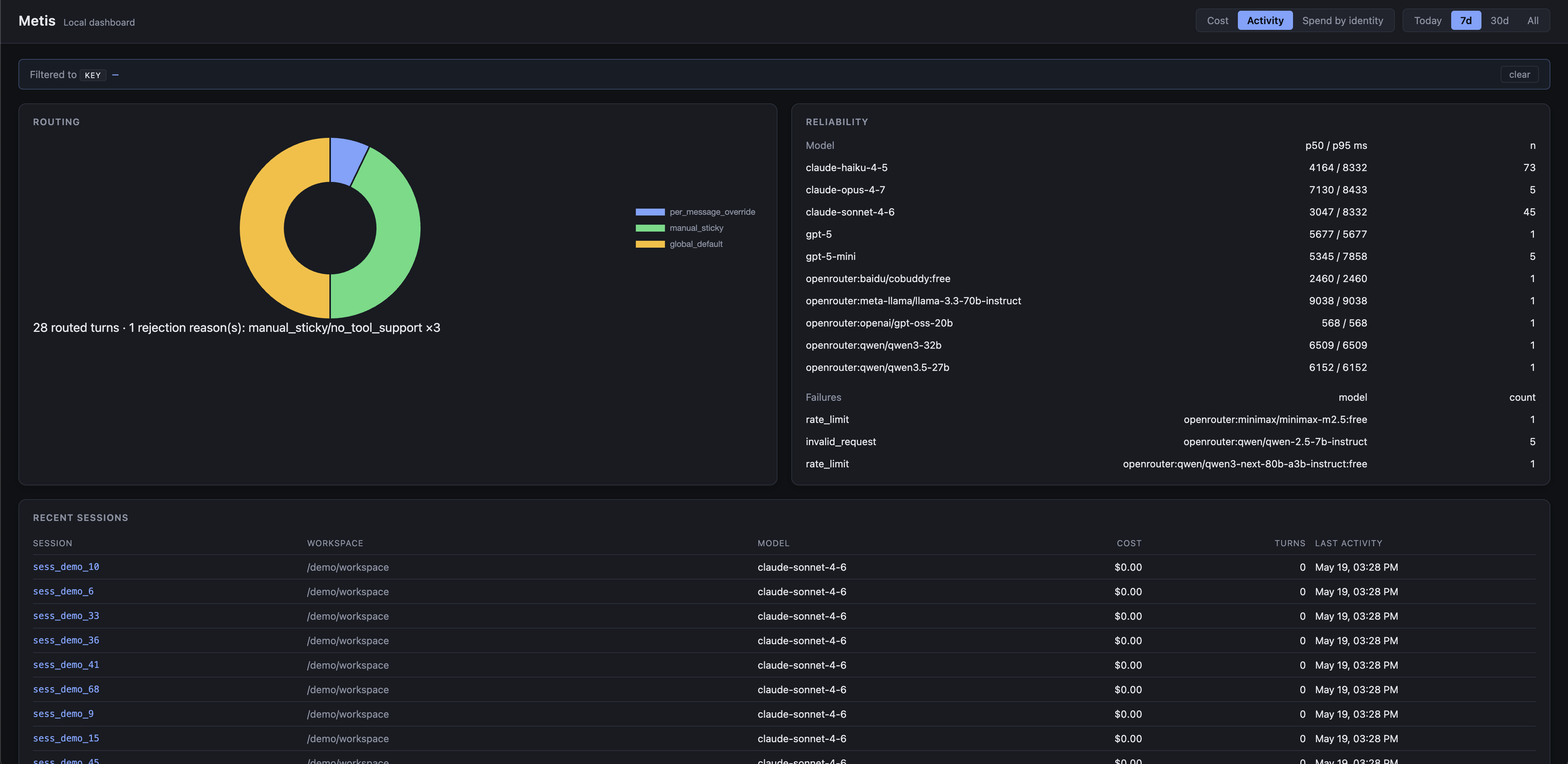
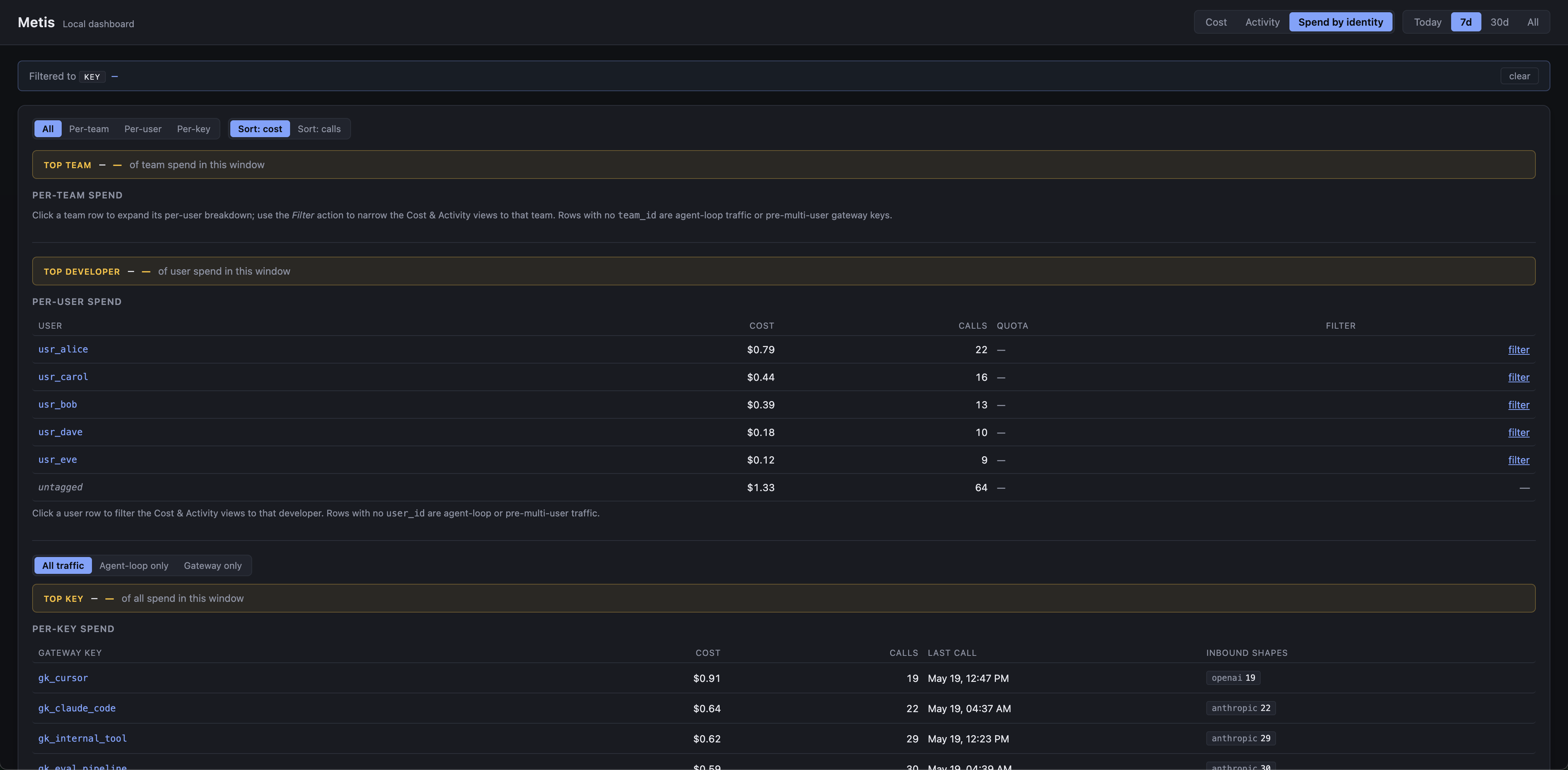
Baseline counterfactual
Every spend total is shown against what the same turns would have cost on a pinned baseline (e.g. claude-sonnet-4-6). Savings stop being a guess and become a number you can put in a board deck.
Per-user / per-team
/analytics/by_user · /analytics/by_team · /analytics/by_key roll up cost, tokens, and call counts per identity. The gateway stamps user_id / team_id on every llm.call_completed.
Cost-per-quality
The evaluator scores every turn through a heuristic + LLM hybrid judge. /analytics/quality joins to route.decided, so the model attributed is the one judged — not the judge's own model.
git log --oneline | head
Where the build is, today.
We'd rather show you the actual state than the eventual one. Live runtime status at status.2sum.ai .
shipped
- Transparent HTTP gateway (OpenAI + Anthropic shapes, sync + SSE)
- Three providers wired: Anthropic, OpenAI, OpenRouter
- Per-user / per-team / per-key cost attribution + Prometheus /metrics
- Pattern store with K-NN cluster routing (slot 4 of 7)
- Hybrid evaluator: heuristic + LLM-as-judge with cost caps
- Worker delegation: planner spawns workers for fan-out
- Audit log + 90-day trace retention + GDPR export / forget
- Stripe-backed billing module (opt-in) for Pro seats + Enterprise savings meter
- GA blocker fixes: NETWORK escalation refinement + bare-model normalization
- Concierge trial CLIs: metis customer-report + metis trial-status
- SOC2 Trust Service Criteria gap audit (Type 1 target Q3 2026)
- Helm chart + Docker compose + < 1-hour buyer-trial recipe
- 1,829 tests passing
in progress
- Context-assembler v3: skill activation paths
- Skill curator (gated on Phase 2.5 agent-authored skills)
- Async / concurrent worker delegation
- Phase 3 promotion decision (owner sign-off on the proposal)
First savings number in under an hour.
Kind cluster + helm install + pre-baked workload + per-key cost rollup, automated end-to-end. The open-core gateway is free to self-host; Pro converts on active seats when a team needs identity, caps, audit export, and the agent.